¶ HIN
O HIN (Harpia Ingestion Node) é o módulo do Harpia SIEM responsável pela gerência das configurações dos nós de ingestão que realizarão a coleta dos logs (eventos) no ambiente do cliente. Todo este gerenciamento é realizado através da própria interface do Harpia.
Sua jornada está dividida em três etapas:
- Provisionamento da máquina do cliente
- Gerência e configuração do HIN na console do Harpia
- Instalação do HIN Client Package na máquina do cliente
¶ Provisionamento da máquina do cliente
A máquina do cliente deverá ser provisionada de acordo com a tabela de requisitos definida em: Requisitos de instalação, observando as configurações dos recursos conforme a volumetria de EPS contratados pelo cliente. Nesta máquina será instalado o HIN Client Package (Pacote de serviços do HIN descrito mais abaixo nesta documentação) que possibilitará a coleta de todos os logs do cliente.
¶ Gerência e configuração do HIN na console do Harpia
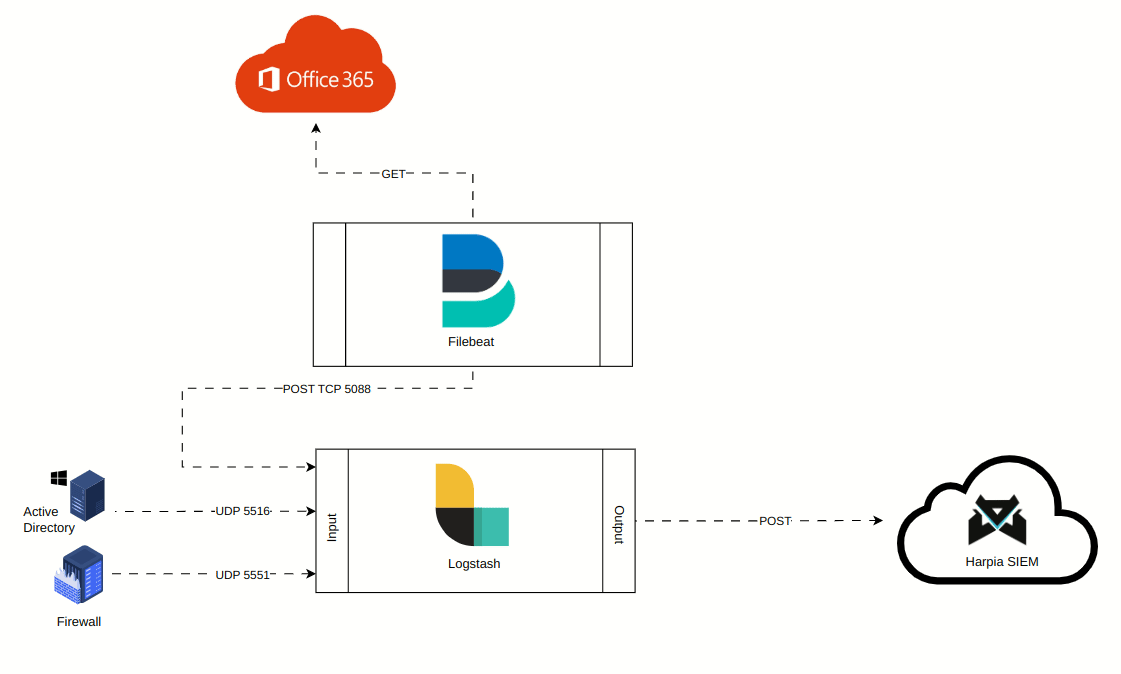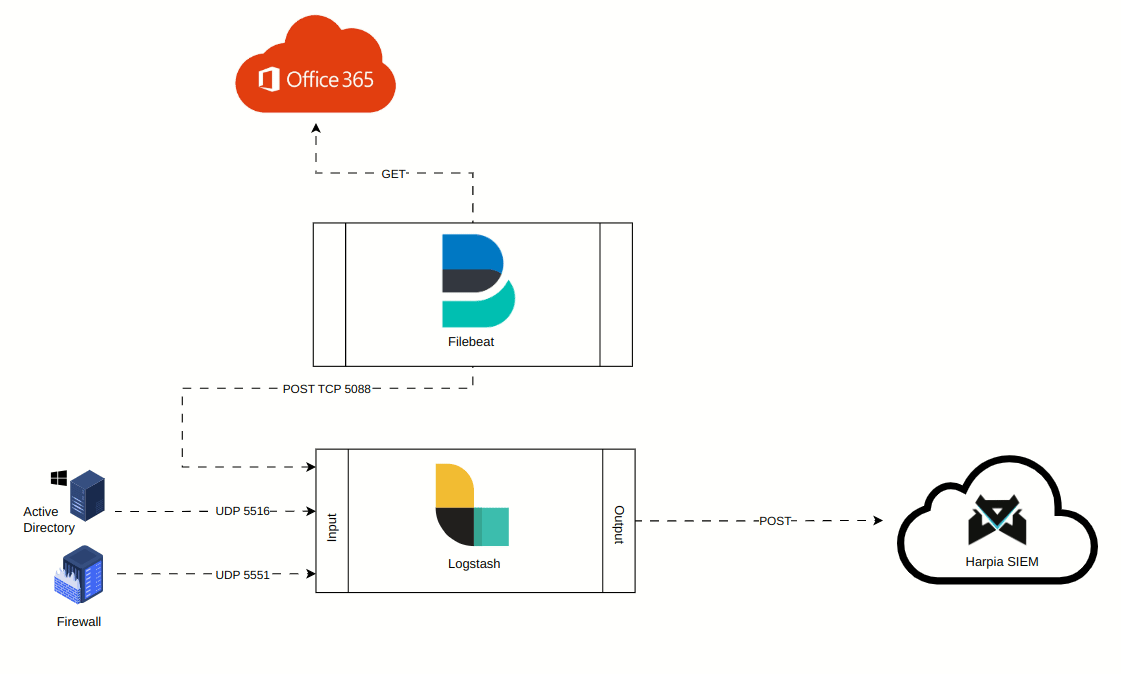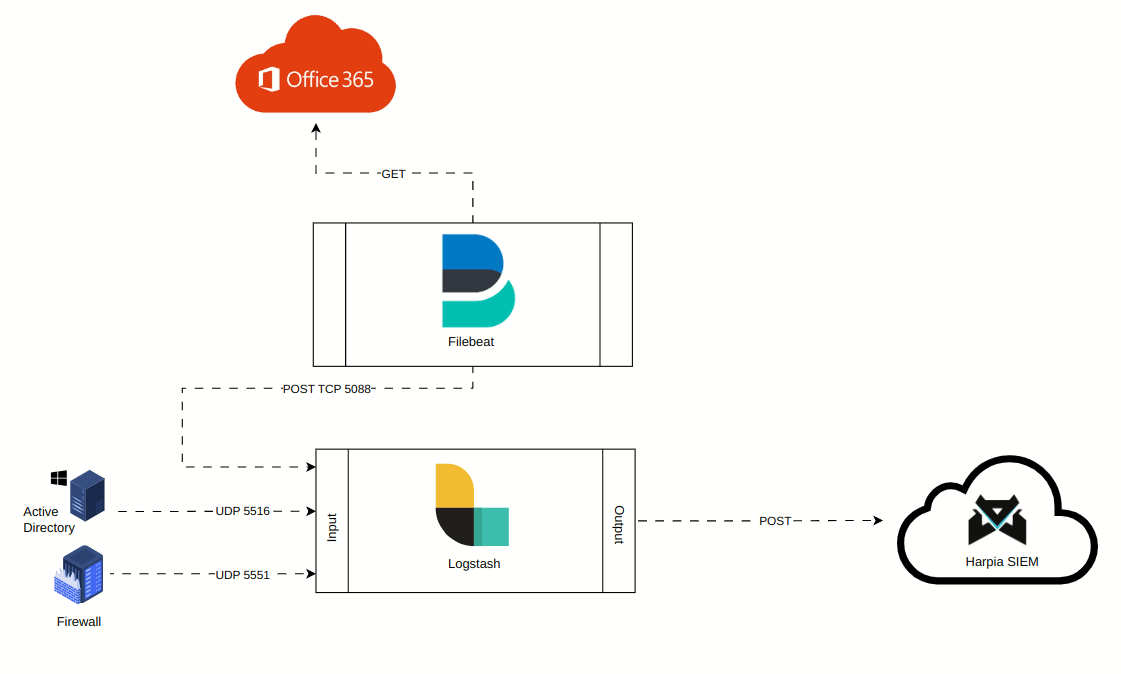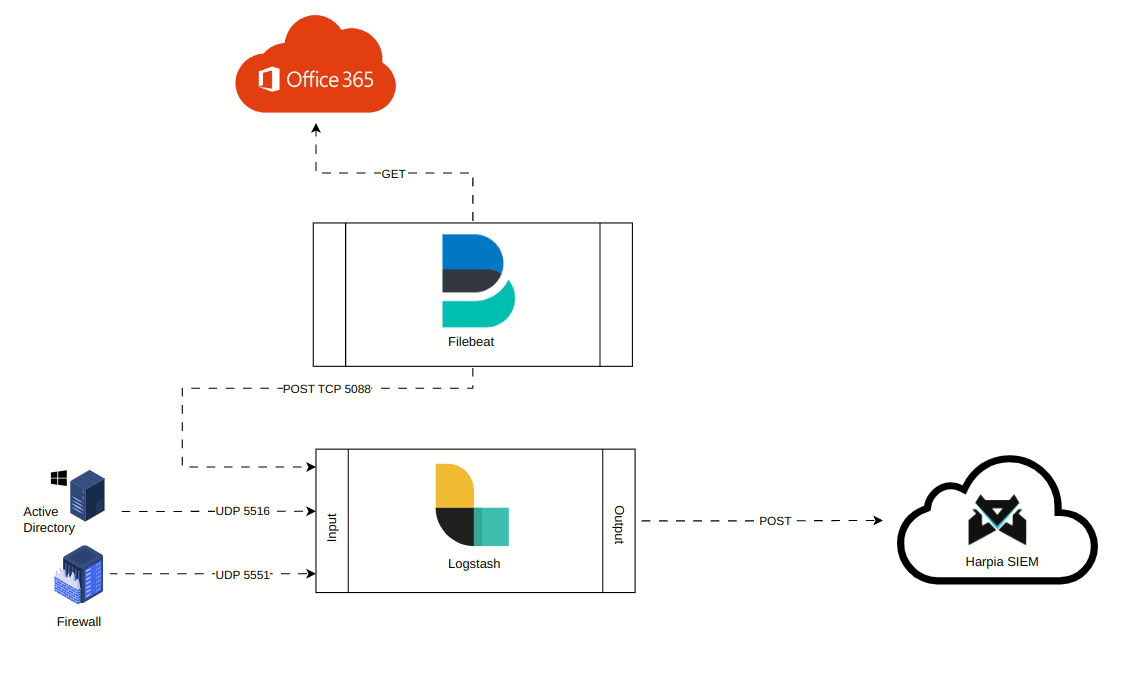
Esta etapa dá início ao processo de comunicação entre o Harpia SIEM e a infraestrutura do cliente. Através da console do Harpia, no menu Ingestion Nodes/Nós de ingestão, será apresentado uma lista dos HIN's pertencentes ao cliente. Esta lista contém informações importantes sobre o HIN, tais como: status de comunicação, saúde no recebimento de logs, sincronização de configurações, quantidade de ativos configurados e associados, entre outras, conforme mostra a imagem abaixo:
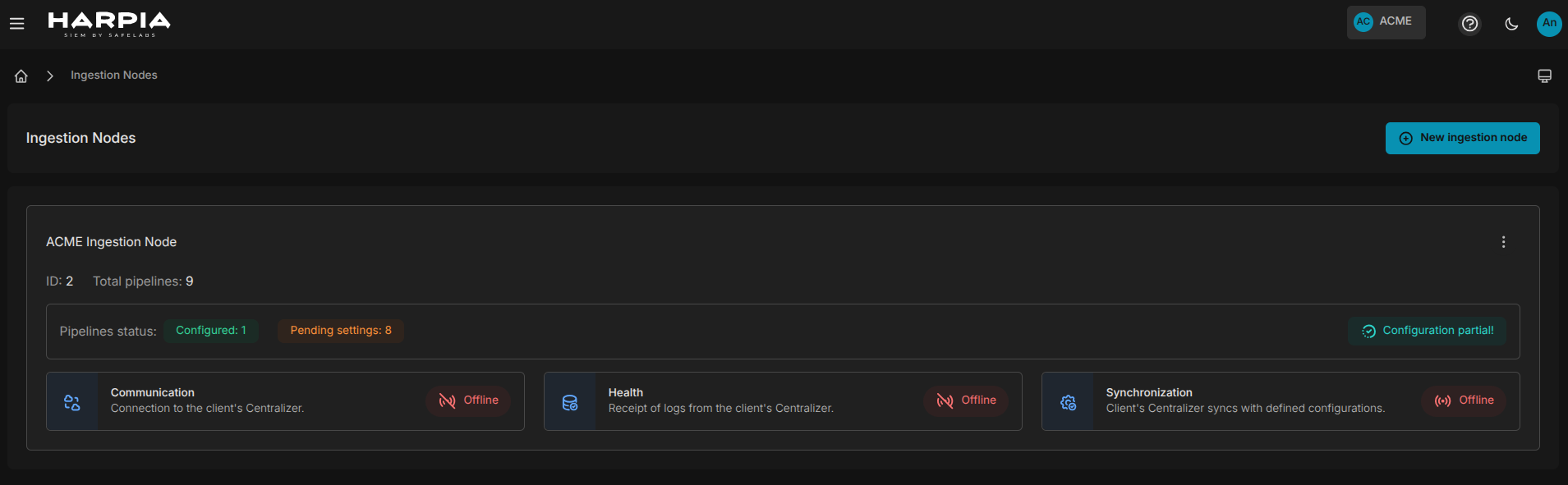
¶ Registro de um novo HIN
Para adicionar um novo HIN acesse o botão New Ingestion Node/Novo Nó de Ingestão acima da lista de HIN's à direita. Na tela que será mostrada você deve adicionar um nome para o novo HIN. Sugerimos um nome intuitivo que identifique o HIN. Ex: ACME Ingestion Node.
Quando o cliente necessitar configurar mais de um HIN, como em situações de distribuição do apontamento para máquinas distintas, é importante definir nomes que tragam unicidade/distinção para os HIN's, tendo em vista que isto será útil para o monitoramento dos mesmos.
Além do nome, uma descrição pode ser adicionada caso julgue necessário.
¶ Pipelines
O Harpia SIEM utiliza o conceito de pipelines para convencionar um fluxo de coleta dos logs do cliente segregando a coleta por datasource, ou seja, para cada fonte de log desejada, uma pipeline distinta deverá ser criada.
Isto ocorre porque são utilizadas duas ferramentas de coleta open-source: Logstash e Filebeat. Ambas realizam coletas específicas, com o Filebeat focado na coleta leve de arquivos e logs de cloud, enquanto o Logstash combina coleta avançada e processamento dos dados. Essa composição oferece uma solução eficiente e flexível para diferentes necessidades de coleta e processamento.
As pipelines podem ser de dois tipos:
- Default - Quando trata-se de uma coleta realizada diretamente pelo logstash. Ex: um input que recebe logs de um firewall na porta 5514 udp, ou ainda uma coleta de S3 bucket da AWS, que utiliza o plugin s3 do logstash.
- Filebeat - Quando a coleta necessita de uma interação extra, Ex: coleta de logs do Office365. Há um módulo específico do filebeat para este tipo de coleta de cloud, o o365, que abstrai e coordena toda questão de conexão, paginação e intervalos de coleta.
O Filebeat fornece ainda dezenas de módulos de coleta com as principais fontes disponíveis no mercado, além de ser flexível permitindo configurações de coleta customizadas, desenvolvidas pelo usuário.
A animação abaixo mostra como foi convencionado o fluxo de dados dos logs para coletas com Logstash e Filebeat. Perceba que mesmo quando utilizando o Filebeat, o fluxo se dá sempre no sentido Filebeat >> Logstash >> Harpia SIEM. Ou seja, não é possível enviar logs diretamente da cloud para o Harpia, nem do filebeat diretamente para o Harpia. O fluxo sempre será centralizando os logs no logstash e o mesmo fará o encaminhamento dos logs para o SIEM.
Contiuando o cadastro do HIN, por padrão o Harpia só permitirá o cadastro de um HIN caso haja ao menos uma pipeline setada. Temos os seguintes campos:
-
Pipeline Name, ou nome da pipeline - Um nome descritivo é indicado. Ex: Forcepoint UDP.
-
Collection Type, ou tipo de coleta - Estabelece se a pipeline é do tipo default (Coleta direta com o logstash), ou se utilizará o Filebeat para coletas mais específicas de datasources de cloud.
-
Description, ou descrição - Caso queira especificar alguma informação pertinente sobre a pipeline, este campo está disponível.
Ao selecionar o collection type como Filebeat, um campo de seleção será mostrado com a lista dos módulos disponíveis. Este campo é opcional, mas caso queira utilizar um dos módulos, selecione o mesmo no campo select e clique no botão "+" para adicioná-lo. Estes módulos são implementações nativas do filebeat que abstraem conexão, paginação entre outros parâmetros facilitando a coleta para os módulos existentes. Basicamente o usuário necessitará informar qual mósulo quer usar, bem como as credenciais do cliente necessárias para a coleta.
Após a configuração de uma ou mais pipelines basta salvar o HIN no botão de registro no canto inferior direito da tela.
Ao registrar uma nova HIN, automaticamente o Harpia irá disparar um email ao usuário contendo o HIN CODE, código de identificação da HIN que será solicitado no momento da instalação do HIN Client Package.
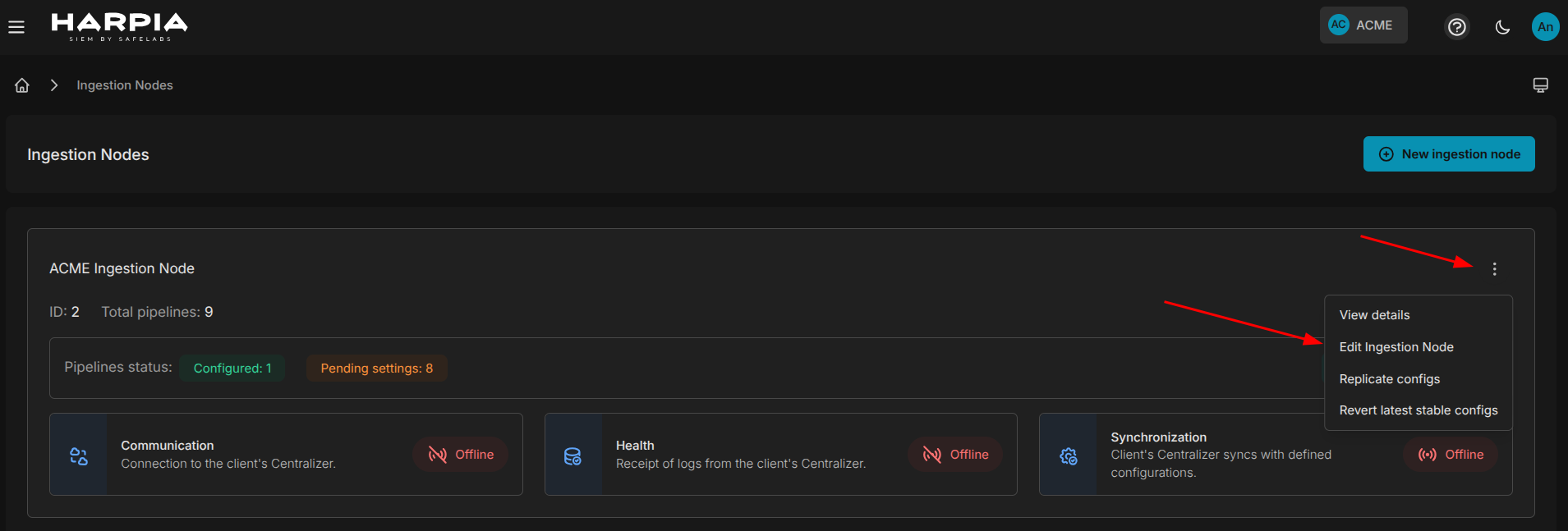
¶ Edição do HIN
Para editar um HIN, basta acessar na tela de lista dos HIN's o botão more actions e selecionar a opção Edit Ingestion Node, como mostra a figura abaixo:
O processo de edição é simples e intuitivo. Nele você poderá adicionar novas pipelines, alterar alguns campos das existentes, bem como excluir alguma pipeline desde que não haja um datasource associado a ela.
Sempre deverá haver ao menos uma pipeline por HIN, o que impede que todas sejam excluídas.
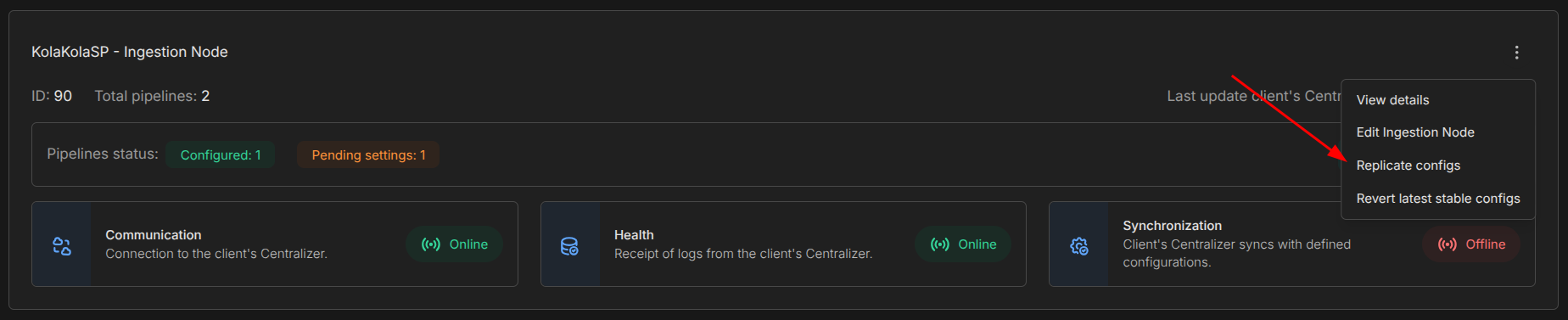
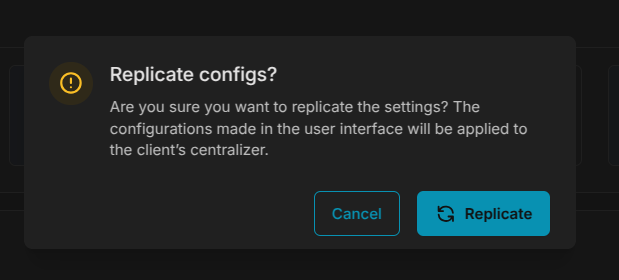
¶ Replicação de Configurações
Após concluir a configuração de uma pipeline, associar um datasource, ou ainda alterar alguma configuração existente, é necessário a realização de uma replicação para que as configurações ajustadas sejam sincronizadas com a máquina do cliente. No botão more actions na lista de HIN's, basta selecionar a općão replicar configurações.
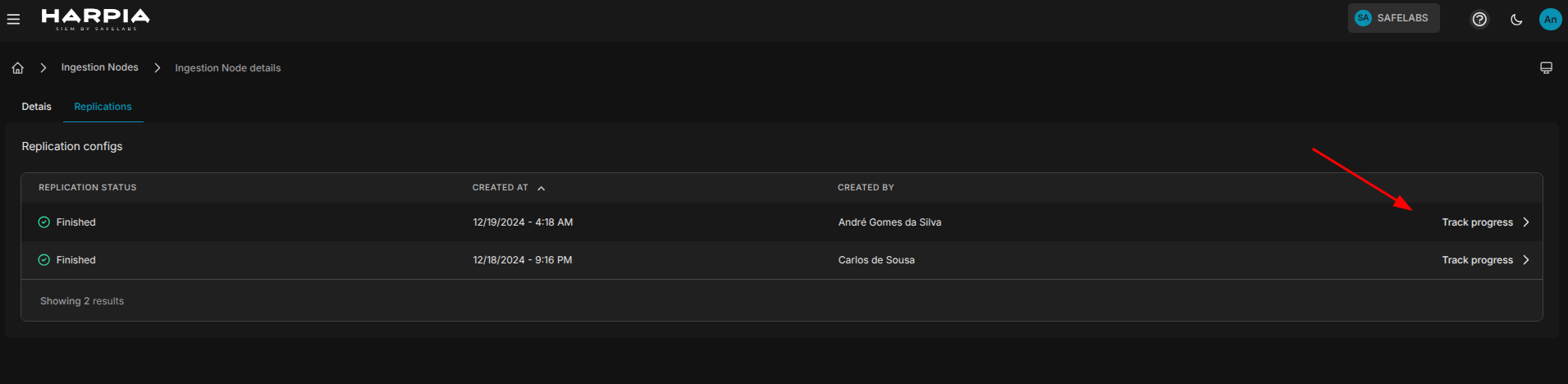
¶ Traceback de replicações
Ao solicitar uma replicação, o SIEM pede que o usuário confirme a operação para de fato iniciar o processo. Após a confirmação, um link para acompanhamento do processo track progress fica visível na lista de HIN's permitindo que o usuário acompanhe em tempo real o processo de deploy das configurações na máquina do cliente. O tracy progress tráz bastante informação útil, reporta falhas e problemas de deploy, ajudando o usuário a realizar o debug e correção nas configurações de maneira rápida e eficiente quando necessário.
Após a conclusão da replicação, as configurações já entram em vigor na máquina do cliente automaticamente.
Todo histórico de tracebacks replicados ficam disponíveis na tela de Detalhes do HIN / na aba replications, como mostra a figura abaixo:
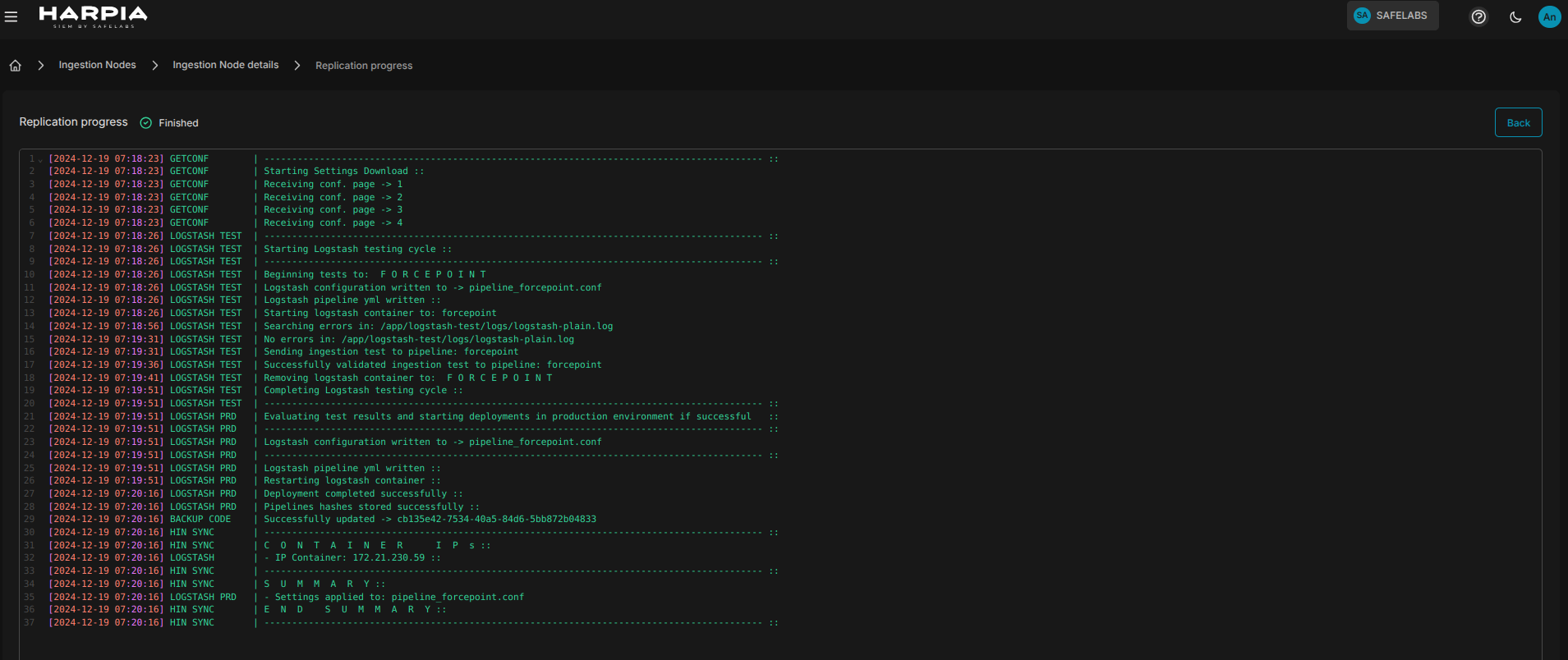
Replicações só podem ser solicitadas quando o status de comunicação com o Client HIN PACKAGE estiver online e também quando houverem datasources configurados e associados.
¶ Reverter configurações para a última estável
Você pode acessar esta tela através da opção more actions presente na lista de HIN's. Ela irá reverter automaticamente as configurações aplicadas no Client HIN Package para a última configuração estável.
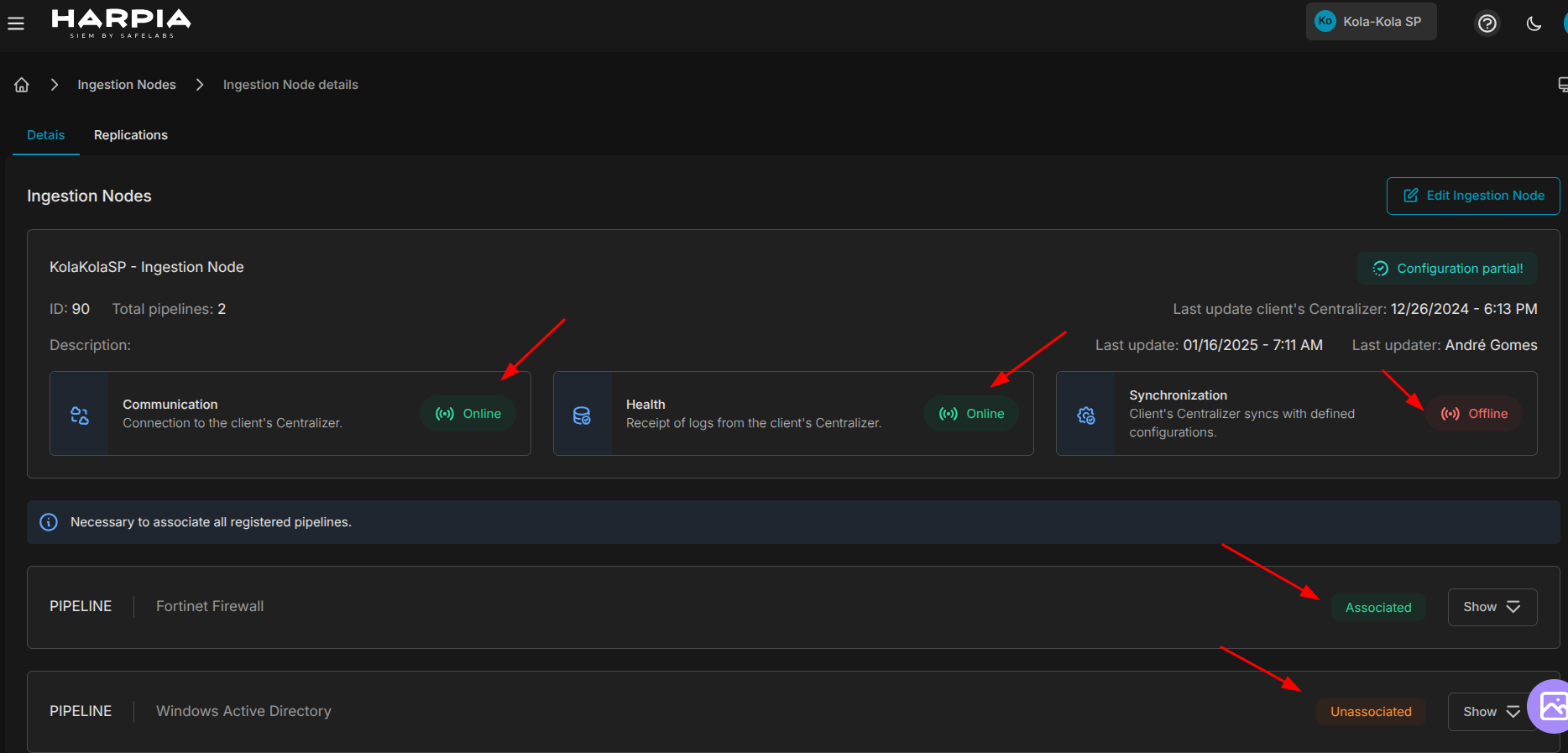
¶ Detalhes do HIN
Você pode acessar esta tela através da opção more actions presente na lista de HIN's. Ela mostrará um resumo de todas as configurações do HIN, as pipelines registradas, inclusive se as mesmas estão associadas a um datasource específico, conforme mostra imagem abaixo:
¶ Instalação do Client HIN PACKAGE
¶ Distribuição
O Client HIN Package é diestribuído ao canal (MSP|MSSP) que realizará a instalação no na máquina do cliente, ou supervisionará a instalação no ambiente do cliente.
¶ Pré-requisitos para a instalação:
Para realizar o processo de manipulação e instalação do pacote você necessitará de alguns conhecimentos em Linux, tais como:
- Utilização do bash linux
- Criação de diretórios
- Cópia de arquivos
- Descompactação de arquivos
- Instalação de pacotes e programas utilizando (yum/dnf/apt dependendo da distro do Linux)
¶ Docker
É necessário instalar e habilitar o docker na máquina do cliente. Ver documentação
Adicione o usuário harpia ao grupo de permissões do docker:
sudo usermod -aG docker harpia
Após a execução do comando acima é necessário realizar logout e logon novamente. (Sugerimos um reboot na máquina)
Certifique-se que o usuário harpia esteja adicionado ao grupo do docker. Isto dispensará a necessidade do uso do root para manipular o client.
¶ Visão geral do Client Hin Package
O Client Hin Package é um pacote de serviços responsável por gerenciar, configurar e monitorar os recursos, bem como o funcionamento da coleta de logs realizados do lado do cliente em tempo real. É uma ferramenta poderosa e proativa na prevenção de esgotamento de recursos ou takedowns na máquina do cliente.
A animação abaixo representa os componentes do package:
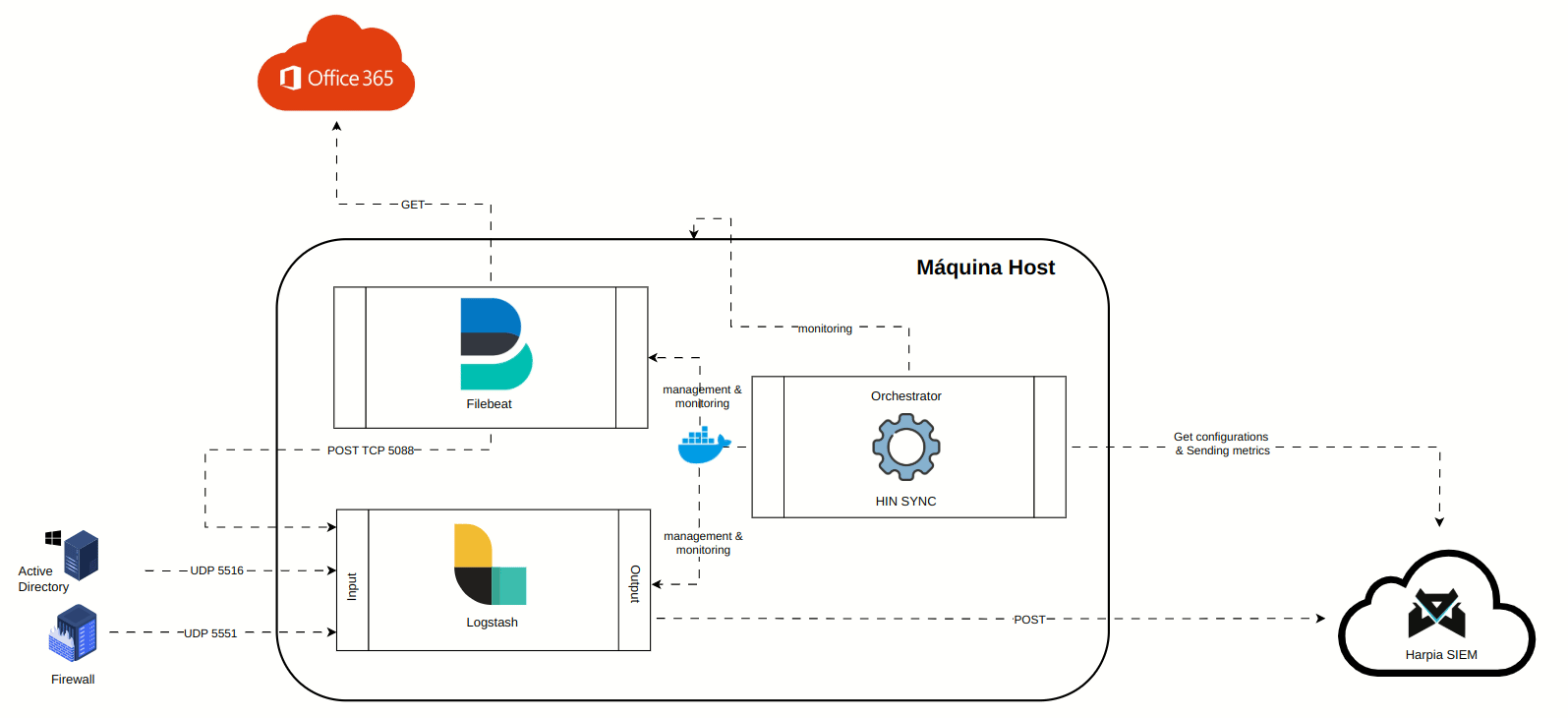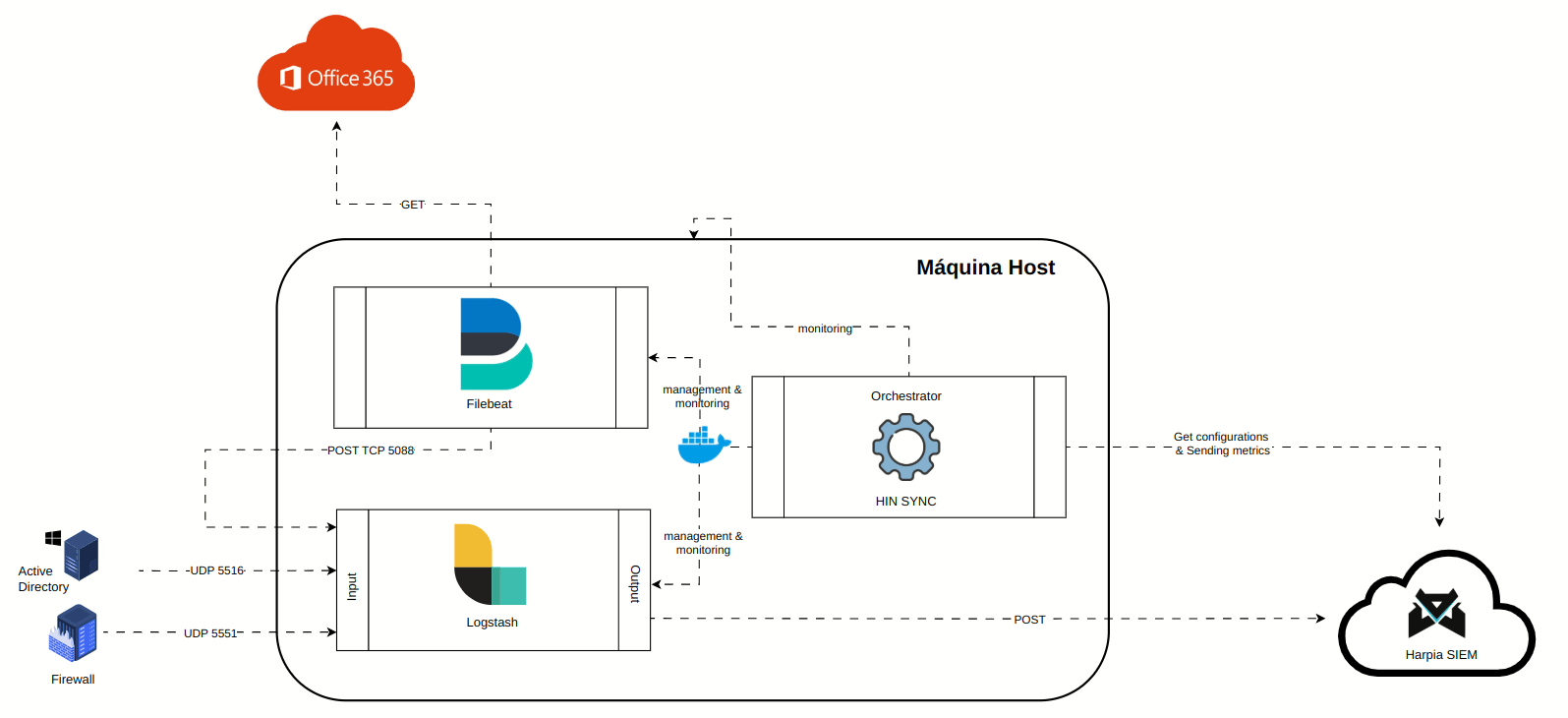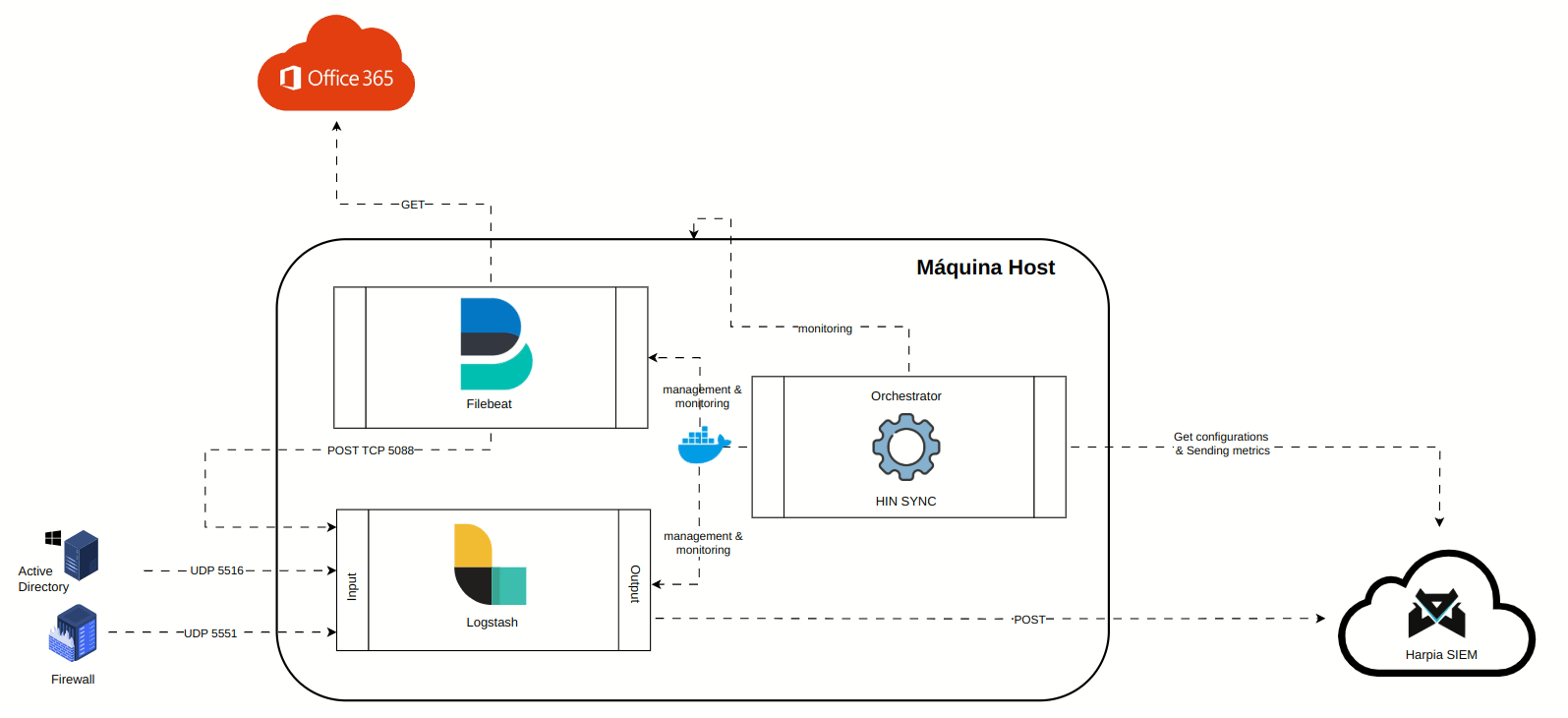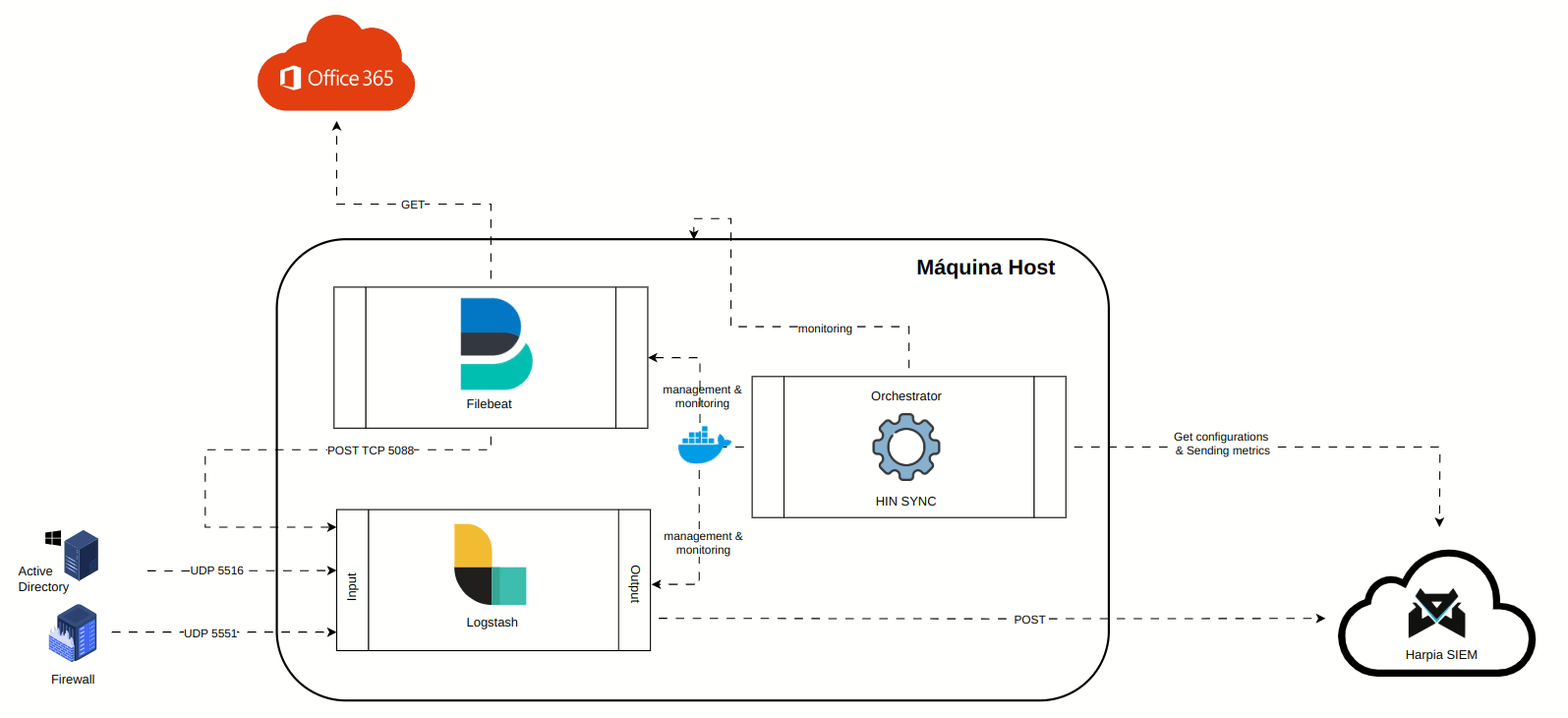
O package é composto por três serviços:
¶ Logstash
Ferramenta de coleta e processamento de logs, que recebe todos os logs apontados e os direciona a cloud do Harpia SIEM. Basicamente possúi uma 3 seções configuraveis:
INPUT - Seção que referencia a origem dos logs. Pode receber diretamente em portas UDP, TCP, Beats (quando recebendo dados via Filebeat), ou via plugin Logstash.
FILTER - Seção que lida com filtros que manipulam, adicionam ou removem campos dos logs. Nesta seção é adicionado um header em cada evento adicionados alguns campos de controle. A imagem abaixo ilustra a seção que insere o header com os campos de controle mencionados:
filter {
mutate {
add_field => {"[device][manufacturer]"=> "akamai_waf"}
add_field => {"[device][class]"=> "Web Application Firewall (WAF)"}
add_field => {"[device][model][name]"=> "default"}
add_field => {"[device][id]"=> "e0cf24a9-29e8-4d77-91ee-09b6bda4a23e"}
add_field => {"[device][centralizer]"=> false}
convert => {"[device][centralizer]"=> "boolean"}
}
}
OUTPUT - Seção que define para onde os logs serão enviados. No caso do Harpia, eles são encaminhados ao HARPIA KAFKA EDGE.
O Logstash permite coletar dados diretamente por protocolos como TCP, UDP e Beats, oferecendo flexibilidade para ingestão em tempo real. Além disso, suporta diversos plugins de input, como kafka, stdin, file, e também plugins voltados a ambientes em nuvem, como azure_event_hubs, google_pubsub e aws_s3. Também é possível configurar entradas manuais usando os plugins http_poller e http, úteis para consultas periódicas ou recebimento de dados via HTTP.
¶ Utiliza Persistent Queue
A persistent queue do Logstash é um recurso que permite armazenar eventos localmente no disco antes que sejam processados e enviados ao destino final. Essa funcionalidade garante maior resiliência ao pipeline, permitindo que os logs sejam retidos em caso de falhas, como interrupção da internet, quedas de destino ou reinícios inesperados. Quando o serviço é restaurado, os dados armazenados na fila persistente são processados e enviados, evitando perda de eventos. Ela é configurada na console do Harpia onde é informado o tamango em GB da PQ para cada data source.
Para aprender mais sobre coletas do logstash, consulte a documentação nas seções INPUT, FILTER e OUTPUT para maiores informações. Ver documentação
¶ Filebeat
Ferramenta de coleta de logs específicos, mais direcionada para coleta de logs de cloud, que faz o download dos logs e os direciona para o serviço logstash. O Filebeat conta com um preset de módulos nativos para coleta dos mais comuns tipos de logsources atuais, que abstraem conexão e paginação de logs, exigindo apenas as credenciais de acesso, chaves de apis e as url do serviço a ser coletado. No entanto, ele também permite a configuração manual de coleta em apis customizadas através de inputs específicos.
Para aprender mais sobre a utilização do Filebeat, consulte a documentação para maiores informações. Ver documentação
¶ Hin Sync
Software proprietário SAFELABS que se comunica com a Cloud Harpia SIEM API, e através desta comunicação orquestra os serviços de configuração do Logstash e Filebeat, bem como o monitoramento proativo todos os três serviços (incluindo ele próprio), além dá máquina host do cliente, coletando métricas de uso cpu, ram e disco em tempo real. Este monitoramento pode ser acompanhado no SIEM através do Channel Center / HIN Dashboard.
Todo Client Hin Package é orquestrado em contâineres Docker, a fim de proporcionar maior simplicidade e isolabilidade entre serviços na máquina do cliente.
¶ Instalação do Client HIN Package na máquina do cliente
Na máquina do cliente deverá ser criado um diretório na raiz do volume configurado pro Harpia, /Harpia. O SAFELABS disponibilizará ao canal um .zip contendo o Client Hin Package, que deverá ser descompactado neste diretório /Harpia. Ao final do processo a árvore de diretórios deverá ser: /Harpia/hin
É preciso garantir que o diretório /Harpia/hin, bem como suas subpastas possuam as permissões 0775. Um outro ponto fundamental é garantir que a lista de URLS estejam com permissões liberadas no firewall do cliente a fim de que consigam ser acessadas pelo package para a instalação de componentes específicos do Client HIN Package.
Para instalar o Client Hin Package, navegue até o diretório /Harpia/hin e execute o comando abaixo:
./install_harpia_hin.sh
A tela inicial de cadastro ho client será mostrada como na figura a seguir:
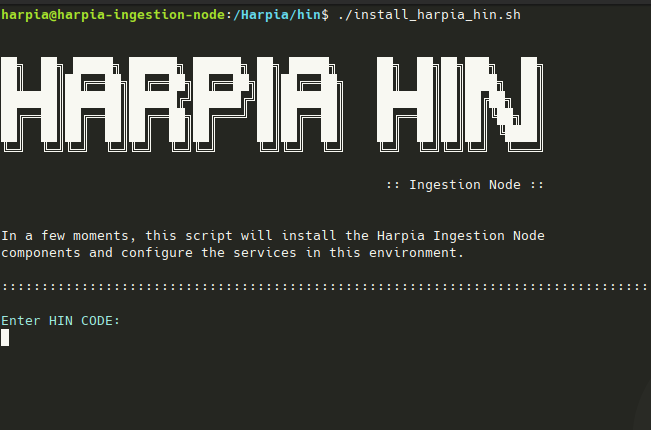
Em posse do HIN CODE, código de identificação da HIN, enviado por email no momento do registro da HIN, informe-o na tela e prossiga teclando ENTER.
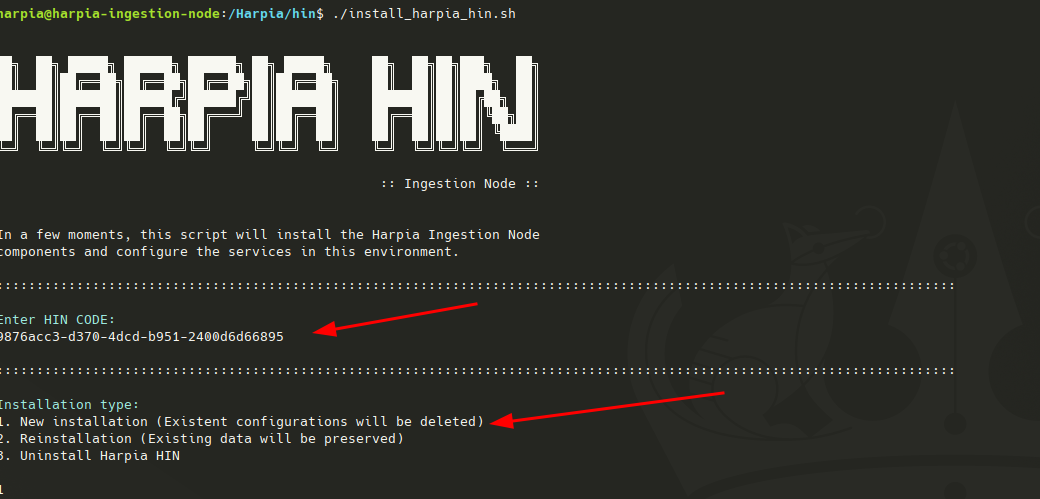
Na sequência informe o tipo de instalação que deseja realizar.
- Instalação nova, removendo configurações existentes.
- Reinstalação, mantem os dados existentes reinstalando apenas os serviços.
- Remove o Client Hin Package da máquina cliente.
Ao final da instalação serão mostradas as informações de cada serviço instalado, bem como um path para a pasta de logs dos serviços, a fim de dar visibilidade ao usuário de cada etapa da instalação dos pacotes, como mostra a figura abaixo:
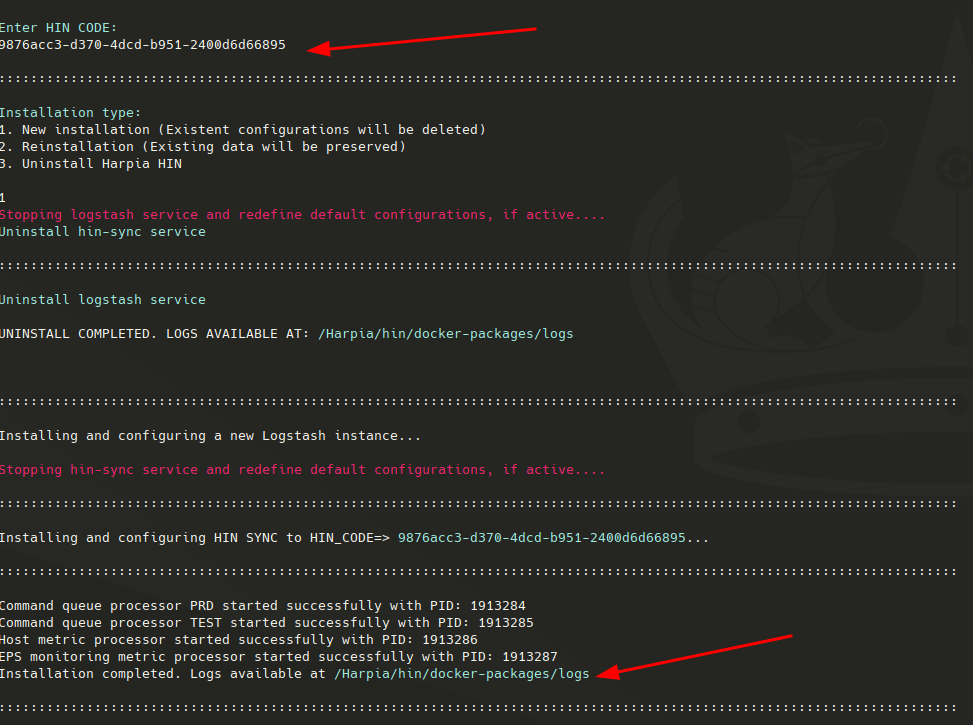
Para verificar se os serviços foram iniciados com sucesso, execute o comando:
docker ps
Ele deverá fornecer uma saída semelhante a imagem a seguir:

Por padrão os serviços hin_sync e logstash são iniciados, conforme mostra a imagem acima. O serviço filebeat é gerado dinamicamente quando necessário, de modo que não será iniciado no começo da atividade do Client Hin Package.
Uma vez concluído o processo de instalação do package, o registro de novas pipelines no HIN do cliente, bem como novos data sources podem ser adicionados diretamente pela console do Harpia e realizada a replicação das configurações. Havendo o fluxo de ingestão completado com a chegada dos eventos no SIEM, os mesmos estarão aptos para consumo das engines de detecção, investigações, API externa de integração com times de SOC, entre outros. Para entender melhor o fluxo completo de ingestão do Harpia, consultar na documentação os itens PARSERS e FONTES DE DADOS.
O processo de instalação do Client Hin Package pode normalmente demorar entre 3 e 5 minutos, tendo em vista que a instalação irá realizar o download e configuração dos principais serviços.